Google announced the release of Gemma 4 12B, a multimodal artificial intelligence model designed to run efficiently on consumer laptops with just 16GB of RAM or VRAM. The model was unveiled between June 3 and June 4, 2026 [1, 2].
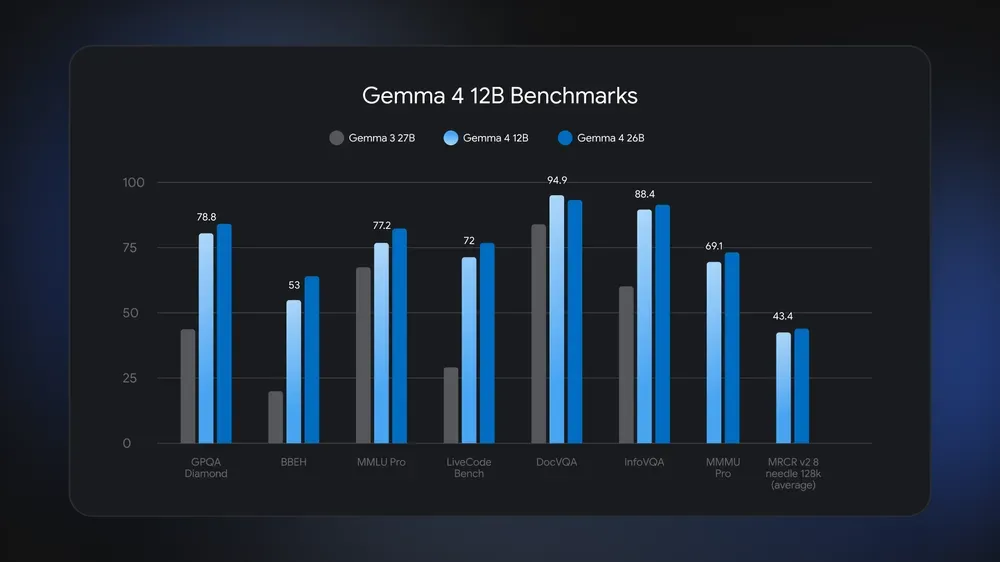
Gemma 4 12B contains 12 billion parameters and closes the gap between Google's smaller mobile-optimized models and its larger 26 billion and 31 billion parameter models. It delivers performance nearly matching the larger 26B model on standard benchmarks, a significant achievement given its smaller size [1, 2].
The 12B model features an encoder-free architecture that processes vision and audio inputs directly within the language model backbone. This makes it Google's first mid-sized model to support native audio input, enabling richer multimodal applications without additional encoders [1, 2].
Launched under the open-source Apache 2.0 license, Gemma 4 12B supports an open developer ecosystem, encouraging broader adoption and experimentation in AI-powered tools [1]. The model uses Multi-Token Prediction (MTP) drafters to reduce latency, providing faster response times during inference [1].
Gemma 4 12B expands the Gemma 4 family, initially introduced in April 2026 with four models: two mobile-optimized smaller versions (E2B and E4B), and two heavy-duty models with 26 billion and 31 billion parameters for more demanding tasks [3, 2]. This new release fills a previously missing middle ground for users needing more power than mobile models but less resource demand than the largest models [3, 2].
The launch makes state-of-the-art multimodal AI accessible to a wider audience since users no longer require high-end hardware to run robust models locally. The 16GB unified memory or VRAM requirement enables deployment on popular consumer laptops [1, 3, 2].
Google plans to support developers integrating Gemma 4 12B into applications, leveraging the model’s efficient architecture and multimodal capabilities to create new AI experiences.